
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- Mobile
- K-sheild Jr
- ZIP
- 디스크
- swing
- Autoware
- 모바일프로그래밍
- Reversing
- Multimedia
- Interceptor
- John the ripper
- 케쉴주
- 포렌식
- K-shield Jr 10기
- 침해사고대응
- upx
- 파일해시생성
- Android
- SW에듀서포터즈
- CodeEngn
- crack
- ctf-d
- tar
- 써니나타스
- shadow
- disk
- 리버싱핵심원리
- Frida
- 안티디버깅
Archives
- Today
- Total
물먹는산세베리아
파이썬 bs4, requests 모듈 이용하여 네이버 실시간 검색어 크롤러 만들기 본문
1. html 열기
이전과 달리 네이버 홈페이지에서 실시간 검색어가 ajax 통신으로 가져오는 방식으로 바뀌면서 키워드로 크롤링을 사용하는 방식이 어려워졌다. 따라서 대안으로 네이버 DataLab에 들어가 크롤링을 시도했다.
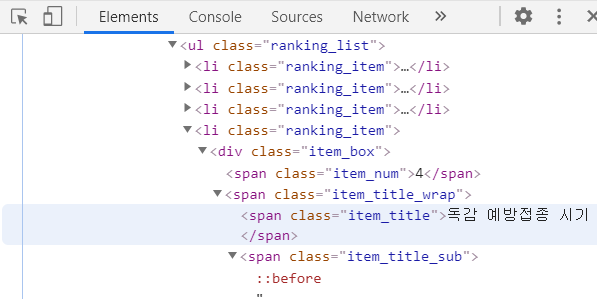
2. 모듈

http 요청을 위한 requests를 import 하였고, bs4 중에서도 파이썬 웹 크롤러 라이브러리 중 하나인 BeautifulSoup을 사용한다.
3. 코드



접속이 차단되었을 때 사용하는 방법으로 User-Agent를 지정해 주었다. 서버에서 봇으로 인지하기 때문에 차단한 경우인데, 이럴 때는 사람이라고 알려주면된다. 그래서 headers 정보에 User-Agent를 넣어주었고, http://www.useragentstring.com/ 여기서 유저 정보를 얻을 수 있었다.
requests.get은 주로 html조회를 요청하는 역할을 하는데, 유저정보를 헤더로 지정하고, Datalab의 주소를 url로 받아 데이터를 요청하였다.
soup을 정의할 때 content를 붙여 response 데이터를 바이트로 리턴하였고 html.parser을 사용하여 html 구조로 인식하도록 만들었다.
그 다음은 span 태그로 되어 있는 item_title 클래스를 갖고 있는 모든 문자들을 찾아 출력시켰다.
4. 실행 결과 및 코드
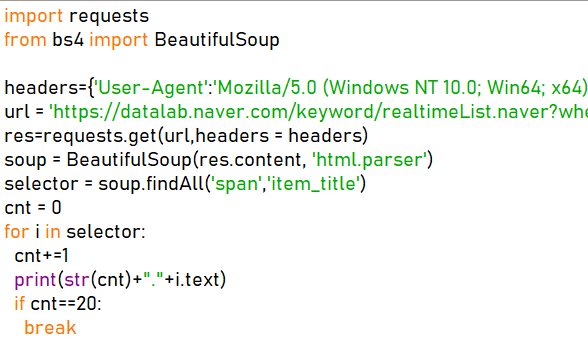
*짤린 부분은 상단 참고

'Language > Python' 카테고리의 다른 글
| pwntools 정리 (0) | 2021.04.28 |
|---|---|
| pwntools(1)_계산문제 (0) | 2020.09.15 |
| 파이썬 소캣 프로그래밍 이용해 파일 보내기 (0) | 2020.09.08 |
| 파이썬 tkinter를 이용해 gui 계산기 만들기(비트연산, 진법 변환) (0) | 2020.09.08 |
| python 소켓프로그래밍으로 1:1 채팅 구현 (0) | 2020.09.07 |
'Language/Python' Related Articles
more



